ICSI Speech FAQ:
2.2 What are the basic approaches to speech recognition?
Answer by: dpwe - 2000-07-22
Essentially all speech recognition systems use the same basic three-stage
architecture:
- Feature detection in which the raw acoustic waveform
is rerepresented in a more useful space, typically a
low-dimensional feature space based on coarse spectral
measurements over a 10-50ms time window.
- Probabilistic classification of the feature vectors,
in which the frames are scored as looking more or less likely
as versions of a number of predefined subword linguistic units.
- Search for best word-sequence hypothesis in which a
word sequence is found that is consistent with the constraints of
lexicon and grammar, and which corresponds to subword unit
sequence that is highly-ranked in the classifier output.
These stages are illustrated in the following overview block diagram:
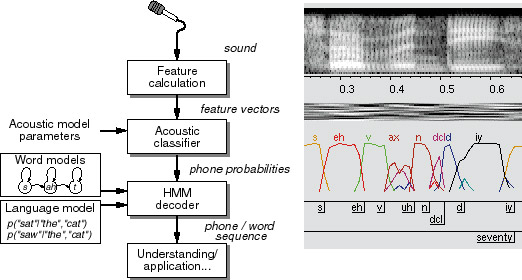
Of course, particular systems may blur the line between these stages, for
instance by involving the subword likelihood estimation as a part of the
search for well-matched word sequences.
Systems can vary at any of these stages.
- For feature extraction, there are any number of different
algorithms to derive feature vectors from speech, differing
in their ability to emphasize linguistically-relevant information
relative to irrelevant information (such as speaker identity),
their robustness to noise and distortion, and their ability
to produce vectors that somehow make the job of classification
easier. However, since the result is, in all cases, a feature
space in which to make classification, varying the feature
extraction has little impact on the overall recognizer architecture;
it merely affects the accuracy.
- Classification can be done by any of the techniques known to
pattern recognition. Early speech recognizers used vector
quantization to reduce the speech features to a discrete
set, then learned associations between particular vectors
and particular subword units. Modern systems learn
continuous classification of the feature vector space, most
often by parametric modeling of the distribution associated
with each speech class, typically with Gaussian mixture models (GMMs).
A significant alternative is the use of neural networks to
discriminatively classify a speech vector (or short sequence),
estimating the probability that it arises from each of the
classes.
- Hypothesis search is usually performed by the hidden Markov model (HMM),
a formulation that expresses the constraints of pronunciation
(lexicon or dictionary) and word sequence (grammar) in a single
finite-state network, for which efficient search and training
algorithms are known. The main alternative is
dynamic time warping, the simpler predecessor to HMMs,
in which template models are stretched and compressed in time
to match the observed features.
At ICSI we have historically used neural nets as our acoustic models
- the so-called 'hybrid connectionist' approach pioneered by Morgan and
Bourlard - rather than the more common Gaussian mixture models. For
a discussion of why, see
the next FAQ answer.
Previous: 2.1 What is speech recognition? - Next: 2.3 Why do we use connectionist rather than GMM?
Back to ICSI Speech FAQ index
Generated by build-faq-index on Tue Mar 24 16:18:13 PDT 2009