Since string and prefix probabilities are the result of summing derivation probabilities, the goal is to compute these sums efficiently by taking advantage of the Earley control structure. This can be accomplished by attaching two probabilistic quantities to each Earley state, as follows. The terminology is derived from analogous or similar quantities commonly used in the literature on Hidden Markov Models (HMMs) [Rabiner and Juang1986] and in Baker:79.
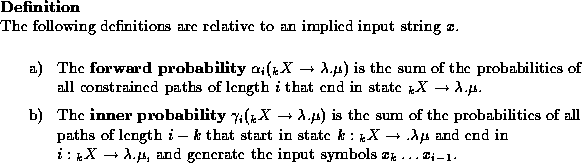
It helps to interpret these quantities in terms of an unconstrained Earley parser that operates as a generator emitting--rather than recognizing--strings. Instead of tracking all possible derivations, the generator traces along a single Earley path randomly determined by always choosing among prediction steps according to the associated rule probabilities. Notice that the scanning and completion steps are deterministic once the rules have been chosen.
Intuitively, the forward probability
![]() is the probability of an
Earley generator producing the prefix of the input up to position i-1
while passing through state
is the probability of an
Earley generator producing the prefix of the input up to position i-1
while passing through state ![]() at position i.
However, due to left-recursion in productions the same state may appear
several times on a path, and each occurrence is counted towards the total
at position i.
However, due to left-recursion in productions the same state may appear
several times on a path, and each occurrence is counted towards the total
![]() .
Thus,
.
Thus, ![]() is really the
expected number of occurrences of the given state in state set i.
Having said that, we will refer to
is really the
expected number of occurrences of the given state in state set i.
Having said that, we will refer to ![]() simply as a probability,
both for the sake of brevity, and to keep the analogy to the
HMM terminology of which this is a generalization.
simply as a probability,
both for the sake of brevity, and to keep the analogy to the
HMM terminology of which this is a generalization.![]() Note that for scanned states,
Note that for scanned states, ![]() is always a probability,
since by definition a scanned state can occur only once along a path.
is always a probability,
since by definition a scanned state can occur only once along a path.
The inner probabilities, on the other hand, represent the probability
of generating a substring of the input from a given nonterminal, using
a particular production. Inner probabilities are thus conditional on
the presence of a given nonterminal X with expansion starting at
position k, unlike the forward probabilities, which include the
generation history starting with the initial state.
The inner probabilities as defined here correspond closely to the
quantities of the same name in Baker:79.
The sum of ![]() of all states with a given LHS X is exactly
Baker's inner probability for X.
of all states with a given LHS X is exactly
Baker's inner probability for X.
The following is essentially a restatement of Lemma 2 in terms of forward and inner probabilities. It shows how to obtain the sentence and string probabilities we are interested in, provided that forward and inner probabilities can be computed effectively.

The restriction in (a) that X be preceded by a possible prefix is necessary since the Earley parser at position i will only pursue derivations that are consistent with the input up to position i. This constitutes the main distinguishing feature of Earley parsing compared to the strict bottom-up computation used in the standard inside probability computation [Baker1979]. There, inside probabilities for all positions and nonterminals are computed, regardless of possible prefixes.