Experiments with Frame Accuracy
Michael L. Shire
Introduction
Previous experiments with LDA temporal filters gave rise to many cases where an improvement in the frame accuracy resulted in either no significant change or a worse word error. This is a problem that has been seen by virtually everyone in the ASR community. These pilot experiments were conducted in an attempt to shed some light on some of the factors that might give rise to instances where frame accuracy and word error correlate or anti-correlate. Many of them are confirmation of commonly known trends. This page is a summary of some recent and hopefully on-going work on diagnosing frame accuracy.
Method
A number of experiments were conducted where a posterior probability (LNA) file was artificially modified to have a specified frame accuracy. First, a base LNA probability file was constructed that had a low frame accuracy rate. The file I used came from a forward pass of PLP [2] with delta and double delta features through an 800 hidden unit MLP. The training data for the MLP was the OGI Numbers [1] training set that had been artificially corrupted by heavy reverberation. The forward pass data was the OGI Numbers development set in the original clean state. The resultant LNA file had a frame accuracy of 45%. I then corrected an additional 25% of the total frames (or 38% of the incorrect frames) to yield a total frame accuracy of 70%. Afterwards, word recognition was performed using the chronos [3] decoder with fixed decoding parameters.
Table 1 Statistics on Original LNA file
|
Number of utterances |
1206 |
|
Number of frames |
216518 |
|
Number of incorrect frames |
118979 (55%) |
|
Number of correct frames |
97539 (45%) |
|
WER (of 4673 words) |
~40% |
|
Number of frames to fix to achieve 70% frame acc. |
54024 (25%) |
I chose to modify a relatively bad LNA instead of constructing a purely artificial one for the following reasons. I wanted probabilities that were generated from real features. An artificial probability file would not have that characteristic. In particular, the distribution of the probability mass in among the non-correct classes would not be trivial to do in a real and principled manner. Lastly, it's easy to do.
Experiments
In all of the following, a total of 54024 mis-classified frames were corrected.
Random Frame Correction
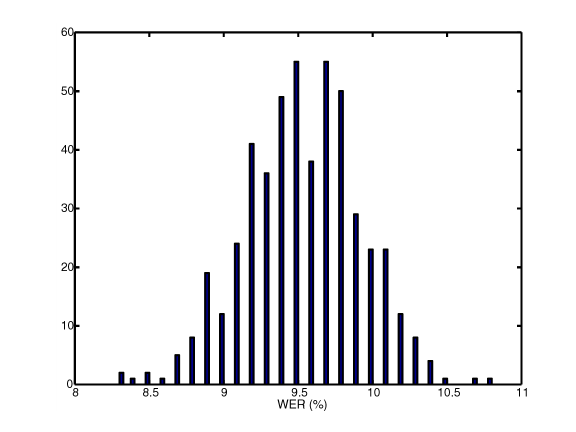
First, I ran 500 word recognition experiments where a fixed number of the incorrect frames were randomly chosen and corrected. This was accomplished by a random shuffling of a list of the incorrect frames with specific random number seeds so that the re-ordering could be duplicated. 38% of the shuffled frames were then chosen and corrected. To accomplish the correction, the incorrect frame was given a value of 0.99 in the correct class phone label position. The remaining probability mass was equally distributed over the remaining phones. A histogram of the results is shown in the following table.
For these 500 recognition tests, all using probability streams with the same frame accuracy, the resulting WER can vary from 8.3% to 10.7%. Those runs with a WER higher than 10% or lower than 9% are significantly different from 9.5%. Note that the original correct frames, 45% of the total frames, were the same for all runs. This test demonstrates that the placement of the correct frames has a significant effect on the WER even though the total correct number of frames remained the same. The frame corrections were randomly chosen. In the following tests, certain frame types were corrected preferentially and resulted in WER scores that sometimes varied by a much wider margin.
Corrected Silence Frames
Correctly determined locations of silence has an important bearing on segmentation, both of words and utterances. This next test makes a further distinction between the silence frames and the non-silence frames within the total number of incorrect frames. Proportions of the silence frames were corrected separately from the non-silence frames.
|
Total number incorrect frames |
118979 |
|
Silence frames incorrect |
17338 (15%) |
|
Non-silence frames incorrect |
101641 (85%) |
In the following figure, the recognition tests were run with varying numbers of corrected silence frames ranging from no silence frames correct to 100% of the silence frames corrected. All the while, the total frame accuracy was fixed at 70% of all frames. Thus, when more silence frames were corrected, fewer non-silence frames were corrected. This was done 20 times with a different random number seeds to select different frames to correct. Again, corrected frames were given a posterior of 0.99 in the correct phone.
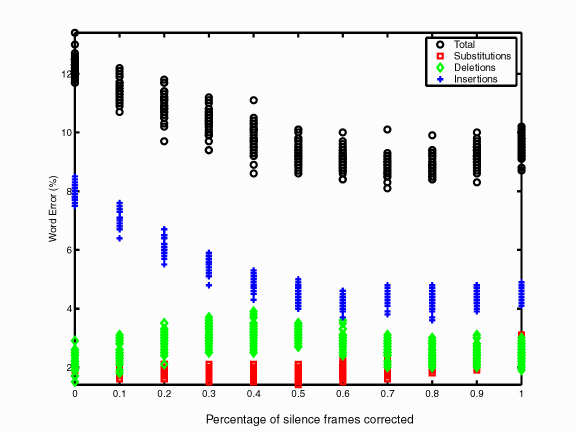
Predictably, the number of insertions has the most prominence in the total word error. As the number of corrected silence frames increases, the number of insertions goes down. Past a certain point (70% of the silence frames), the number of substitutions begins to rise, possibly due to less non-silence frames being corrected. In these tests, the number of corrected silence frames and the WER are strongly (and negatively) correlated with a coefficient of -0.86. Further, silence constitutes only 15% of the incorrect frames, but makes a significant impact. Correct detection of silence is important for low WER.
Corrected Vowel Phones
In this next test, I repeated the previous test except I distinguished vowel phones from the remaining phones (including silence). Vowels largely constitute the syllable nuclei. Therefore, this also tests to some degree the importance of syllable nuclei versus non-nuclei except that silence is a competing factor.
|
Total number incorrect frames |
118979 |
|
Vowel frames incorrect |
44541 (37%) |
|
Non-vowel frames incorrect |
74438 (63%) |
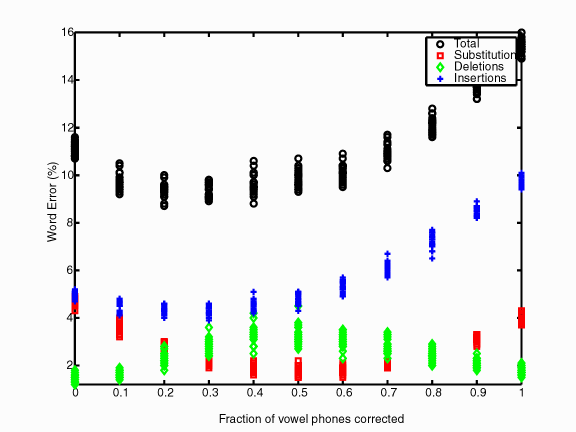
In this test, the percentage of vowels corrected is correlated with WER with a coefficient of 0.76. This indicates that less attention should be paid to vowels versus all else. However, the principal error in the total is the insertions. Since silence is also important for eliminating insertions, it is possible that the reduced number of silence phones corrected is overtaking the corrected vowels. For this reason, I sectioned out the silence for more controlled tests.
Separating out the silence
In this test, all silence frames were corrected and the remaining portion of the corrected frames varied between the vowel and non-vowel phone classes.
|
Total number incorrect frames |
118979 |
|
Vowel frames incorrect. |
44541 (37%) |
|
Silence frames incorrect |
17338 (15%) |
|
Non-vowel, non-silence frames incorrect. |
57100 (52%) |
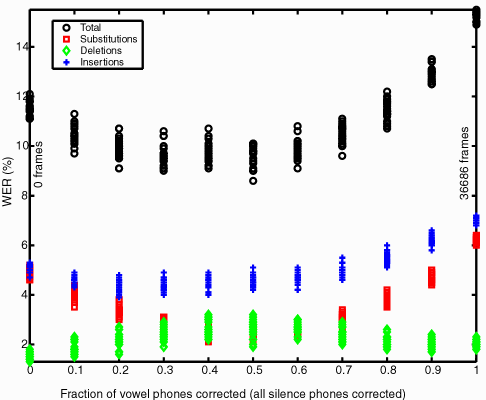
With the silence phones somewhat removed from consideration, the fraction of vowel phones corrected has a correlation coefficient with WER of only 0.56. The fixed silence phones reduced the number of allowed corrections so only 36686 of the 44541 frames could be corrected. Substitutions seem to follow the total WER best though it is not the principal error type.
The following figure repeats the above except that none of the silence frames are corrected (and therefore all of the vowel frames were subject to correction). Here, the correlation coefficient between the fraction of vowels and the WER is 0.045, a very weak correlation. The insertions due to the uncorrected silence frames increases the WER level to between 12% and 16%. At this level it appears that a more or less equal proportion of vowels and non-vowels is needed.
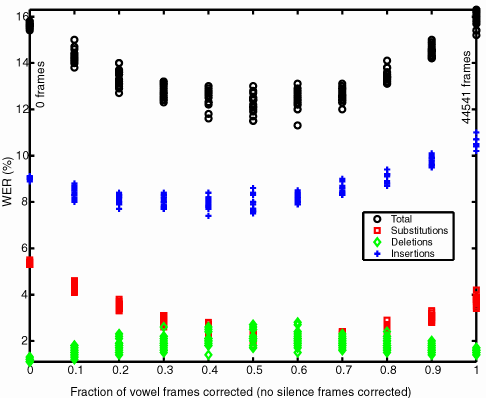
There seems to be a balance between vowel and non-vowel phones such that some number of each is best. However, from the extremes (none or most vowels corrected) and from the correlation coefficients, it appears that correcting the consonants offers the greater benefit, but only slightly when the insertions are high.
Frames bordering phone transitions
This test looks at those incorrect frames that border the transitions from one phone to another (from the transcription). That is, an incorrect frame is counted if an adjacent correct phone is different from the current correct phone.
|
Total number incorrect frames |
118979 |
|
Incorrect frames bordering transitions. |
25605 (22%) |
|
Incorrect frames not bordering transitions. |
93374 (78%) |
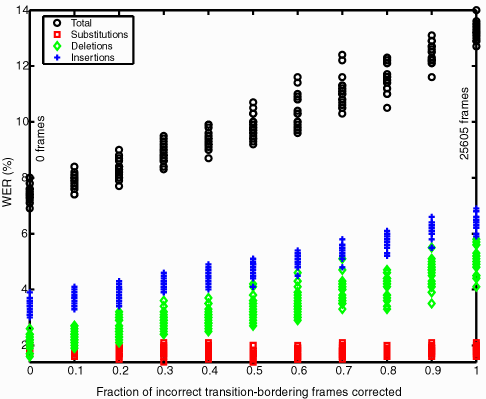
The fraction of corrected transition-bordering frames is strongly correlated with WER with a coefficient of 0.97. It would seem best not to waste resources attempting to get good precision with the transitions phones. Precise placement of transition between phones is dubious at best to begin with.
I also conducted a test where I allow correction of incorrect frames that border the transition-bordering frames. That is, frames that are two away from the transition are candidates for correction.
|
Total number incorrect frames |
118979 |
|
Incorrect frames up to 2 away from border transitions. |
47223 (40%) |
|
Incorrect frames not within 2 frames from border transitions. |
71756 (60%) |
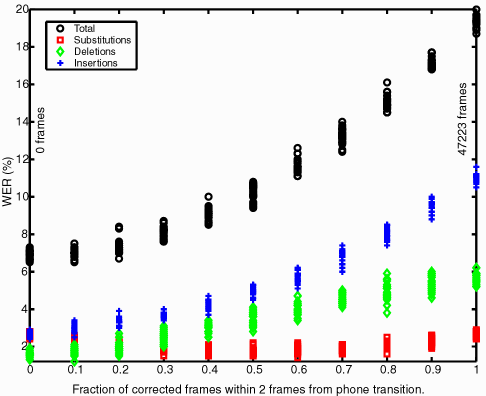
Again, the fraction of corrected frames is strongly correlated to WER with a coefficient of 0.97. It is interesting to see the WER raise from about 7% to almost 20%. All experiments have exactly the same frame accuracy. The only difference between the extremes is that at the low end, non-transition-bordering frames were corrected with all transition-bordering frames left unaltered; and at the high end, all of the transition-bordering frames were corrected with relatively few (6801) of the remaining frames corrected. From these tests, it seems that corrections that are near the centers of the phones are more important than near the boundaries. In fact the average WER when assigning corrected frames away from the transition borders is lower than the average WER from a uniform random assignment (histogram in the first figure).
Setting the Posterior
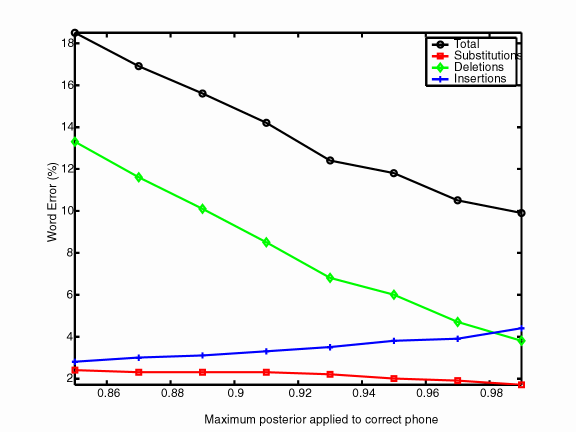
And now we get to perhaps the most disturbing result. In the previous tests, we corrected frames by assigning a high posterior of 0.99 to the correct phone class and the remaining probability mass equally among the rest of the phone classes. However, frame accuracy is a summary based upon the maximum posterior accuracy. The value of the maximum posterior can be much lower (as low as 1/(#phones) + e ). I ran a test where I lowered the probability that was assigned from 0.99 to 0.85 in 0.02 decrements. Results from a single run using a fixed sequence of corrected frames is in the following figure.
 .
.
Varying the maximum posterior to something less or more "confident" significantly alters the resulting WER. So in the above figure, even though each data point is from a probability file with the exact same frame accuracy with the exact same frames classified correctly, the WER can vary between 10% and 18%. This is not so difficult to believe since the decoded path must rely on the confidence of neighboring frames. Admittedly, the experiment is artificial and the pattern of frame probabilities is no longer "natural". The incorrect frames were fixed randomly with possibly many isolated among a group of incorrect frames. A high posterior in a particular frame was necessary to force a new search path and overcome the deficiency in the surrounding frames. This is a possible shortcoming of the technique I have chosen to use here. However, correction with a high posterior, as done with most of the tests, is indicative of the importance of the placement of correct frames.
Discussion
From these tests, the frame accuracy is not necessarily a proper measure when comparing the acoustic probabilities of two or more streams. A frame accuracy weighted by the posterior or a related measure might be more indicative as to which of two probability streams is "better". Additional weighting could be included if it is determined that certain types of frames are more important than others in the resulting decoding. For example, the silence frames are relatively important where as the transition bordering frames may not be. Of course, further tests are needed for a better picture.
History