Earlier we implemented SHRUTI-CM5, a reasoning system for the highly parallel CM-5 platform. More recently, we modified SHRUTI-CM5 to implement a pilot system for computing threaded derivations on off the shelf desktop computers. The pilot system is implemented in C and runs under both Solaris and Linux.
The performance of any reasoning system is highly sensitive to the structural properties of a KB. Moreover, it varies widely from one query to another depending on the properties of the derivation required to answer the query. Thus a system's performance is best specified in terms of mean times required to process a large number of queries with respect to several KBs of varying size and structure. Since we did not have access to very large first-order KBs , we generated several synthetic first-order KBs using KBGen (Mani, 1995), a tool for generating synthetic KBs from a specification of KB size (number of predicates, rules, facts, entities, etc.) and gross structure (number of domains, density of inter and intra-partition connectivity, etc.).
In general, it is assumed that most of the KB predicates can be "partitioned" into domains such that while predicates within a domain are richly interconnected by rules, predicates across domains are interconnected only sparsely. Table 1 displays key parameters characterizing the KBs used in the pilot experiments described below.
| Parameter | KB-S1 | KB-S2 | KB-S3 | KB-S4 |
|---|---|---|---|---|
| KB Size | 210,875 | 500,000 | 1,300,000 | 2,112,000 |
| # Rules | 50,875 | 150,000 | 400,000 | 612,000 |
| # Facts | 100,000 | 225,000 | 600,000 | 1,000,000 |
| # Predicates | 25,000 | 75,000 | 200,000 | 300,000 |
| # Entities/Concepts | 35,000 | 50,000 | 100,000 | 200,000 |
| % Mult-Ant Rules | 67 | 67 | 67 | 67 |
| % Mult-Inst Rules | 25 | 25 | 25 | 25 |
| # Domains | 135 | 250 | 410 | 500 |
| % Inter-domain Rules | 2 | 2 | 2 | 2 |
| Type structure depth | 8 | 8 | 10 | 10 |
Table 1: The size and structure of four synthetic KBs used in the experiments performed with the pilot reasoning system. "% Multi-Ant rules" refers to the percentage of rules with multiple antecedents. "% Multi-Inst rules" refers to the percentage of rules in which a predicate occurs in both the antecedent and the consequent. Such rules lead to multiple instantiations of a predicate. "% inter-domain rules" refers to the percentage of rules that connect predicates to other predicates outside their domain.
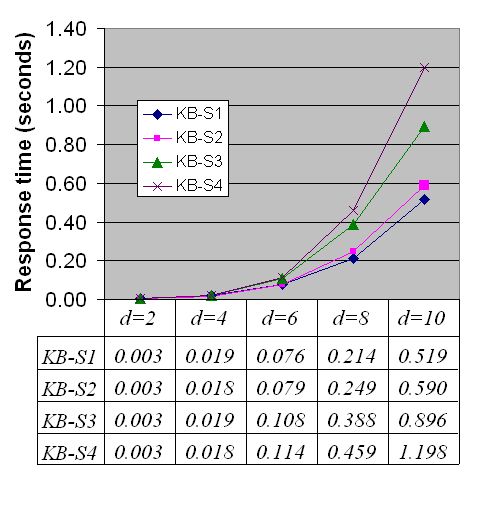
The pilot reasoning system was tested on a Sun Fire V60x 2.8GHz Intel Xeon processor with 3GB of memory running Linux. The pilot system ran on a single processor and did not make use of the dual processor configuration of the Sun Fire V60x. Four hundred to five hundred queries were generated for each of the four KBs and executed to obtain data about response time and memory usage for different depths of inference. Figure 1 displays the average response time of the pilot system to queries (involving at least 3 variables) as a function of the depth of inference (d). The pilot system propagated 100 distinct markers (m=100) and supported up to 25 multiple instantiations per predicate (k=25). These parameter values were found to be sufficient for processing queries up to an inferential depth of 16 (the maximum depth tested).
As seen in the graph, the system can draw threaded first-order inferences extremely rapidly with respect to KBs containing more than two million items.
Fig. 1: The average response time of the pilot reasoning system for different depths of inference (d) for four KBs characterized in Table 1. To reduce clutter, standard deviations are not plotted. The standard deviations of response times for KB-S3 are 0.002, 0.014, 0.084, 0.244, and 0.516 seconds, respectively, for depths 2, 4, 6, 8, and 10. The standard deviations of other KBs are analogous.
In the past, we leveraged the results of our work on neurally motivated models of reflexive reasoning to implement a high-performance knowledge-based system on the CM-5, a commercial hardware platform. The system, SHRUTI-CM5, was developed by D.R. Mani as part of his doctoral dissertation.
SHRUTI-CM5 has been tested on a number of artificially generated knowledge bases. These knowledge bases were constructed automatically from a specification of their gross structure in terms of parameters such as the number of rules, facts, types and objects; the subdivision of the knowledge base into domains; the ratio of inter- and intra-domain rules; and the depth of the type hierarchy.
Even with knowledge bases containing over 500,000 rules and facts we have been able to obtain responses to a range of queries requiring derivations of depth eight in under a second.
We have also encoded WordNet and obtained response times ranging from a few to a few hundred milliseconds for typical WordNet queries. More importantly, the CM-5 implementation provides significant speedup compared to the serial Wordnet system. In our experiments, we obtained speedups as high as 457 for queries such as ``What are the sub-types (hyponyms) of Birds'' which activated a large number of entities.