There are two major differences of interpretation of encapsulation between SK and S1.
S1 interprets ![]() per-class; that is, code may invoke a
private method on another object of the same class. SK interprets
per-class; that is, code may invoke a
private method on another object of the same class. SK interprets
![]() per-object; it is not legal to dot into private
methods. In SK private methods may only be called implicitly on
per-object; it is not legal to dot into private
methods. In SK private methods may only be called implicitly on
![]() . In this sense, SK has a stronger notion of privacy
than S1.
. In this sense, SK has a stronger notion of privacy
than S1.
S1 requires that the creation and initialization of an object execute code in the object's class, and that access to private attributes by code outside of the class be strictly impossible, even by pickling - converting entire data structures to and from a common format for persistence or debugging. In this sense, S1 has a stronger notion of privacy than SK.
The implications of these differences are far-reaching:
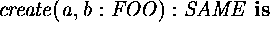
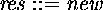 ;
;
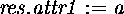 ;
;
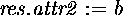 ;
;
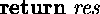
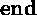 ;
;
Because this is so common, S1 provides syntactic sugar ![]() for
calling
for
calling ![]() . This sugar also provides type inference.
Because
. This sugar also provides type inference.
Because ![]() is only effective within the class, it isn't
possible to create uninitialized objects outside of the class.
is only effective within the class, it isn't
possible to create uninitialized objects outside of the class.
In the S1 idiom, the ![]() routine creates a new
object and then fills in the attributes. SK can't do this if
the attributes are private. Instead, in SK,
routine creates a new
object and then fills in the attributes. SK can't do this if
the attributes are private. Instead, in SK, ![]() creates a
new, uninitialized object, but this may occur outside of the
class. For example
creates a
new, uninitialized object, but this may occur outside of the
class. For example ![]() creates a new object of class T.
There is additionally an operator
creates a new object of class T.
There is additionally an operator ![]() which creates an
object of the same type as an argument. Furthermore the
structure expression allows filling in of public attributes
in the textual order they were defined in the class. If class
T has two attributes
which creates an
object of the same type as an argument. Furthermore the
structure expression allows filling in of public attributes
in the textual order they were defined in the class. If class
T has two attributes ![]() and
and ![]() defined in that textual order,
defined in that textual order, ![]() creates an object
of class T where a is assigned to
creates an object
of class T where a is assigned to ![]() and b
is assigned to
and b
is assigned to ![]() . Alternatively, this can be
made explicit by
. Alternatively, this can be
made explicit by ![]() .
.
Observation for S2: a compromise that would allow the per-object
privacy of SK with the simplicity and encapsulation of S1 would be to
somehow distinguish special methods such as ![]() which would
automatically have a new object as
which would
automatically have a new object as ![]() .
.