

Up: Differences between Sather-1.0 and
Previous: 9 Handling of built-in
There are many language differences that do not appear to fit in one of
the above catagories, and are listed here for future discussion. These
differences may be ascribed to poor communication, different timings of
the language design, or other goals not mentioned here.
- S1 disallows implicit disposal of return values. SK allows it.
Recommendation for S2: disallow implicit return value disposal.
- SK has implicitly defined
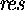 while S1 does not. SK uses
while S1 does not. SK uses 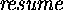 which S1 uses
which S1 uses 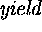 .
. - SK allows implicit coercion (for example, between ints and floats). S1
does not. Implicit coercion is dangerous because precision can be
silently dropped.
Recommendation for S2: allow implicit coercion only
where precision may not be lost, or disallow it.
- SK defines lots of syntactic sugar for characters that S1 doesn't. Some
are not compatible with S1 sugar, such as S1's
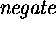 .
. - In SK, most errors turn into catchable exceptions. In S1, most
aren't. The question is what are acceptable semantics for production
code where events that could raise exceptions that would be caught are
not checked because the user wants maximal efficiency.
- S1 disallows multiple types in when clauses of typecase statements to
avoid textual ambiguity when there are iterators. SK allows it.
- SK has dynamic constants, which are variables that may only be
assigned at declaration. S1 has no equivalent feature. The S1
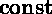 is a
is a 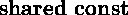 in SK. Similarly, SK calls what S1 calls
in SK. Similarly, SK calls what S1 calls
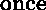 .
. - The base library classes are very different. In SK there are
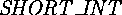 and
and 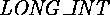 classes,
classes, 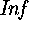 and
and 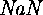 are keywords, instead of
are keywords, instead of 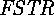 there is
there is
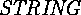 , SK has a
, SK has a 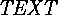 class, output is done differently.
class, output is done differently. - The S1 and SK exception mechanisms are very similar, except that in SK
the raised type must subtype from
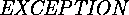 .
.
Recommendation for S2: we should consider making raised types
part of signatures as is done in Modula 3.
- S1 uses a
different syntax for closure and closure types than SK's bound
routine and bound types.