recogviz is an [incr Tcl] program that displays a number of stages of the recognition process. It was originally developed as a spin-off from the BeRP demo, but oriented towards inspecting offline-calculated data rather than live speech input.
The intended operation is as follows: You configure the script (through a config file, eventually, I suppose) to use the feature file, classifier net and decoder parameters that you are researching. You then run the program, and it gives you a display of all the utterance IDs in your pfile (which it got from the listfile you pointed it to, of course). You can then click on difference utterance IDs and it will display the results of running one or more recognizers on that utterance, e.g.:
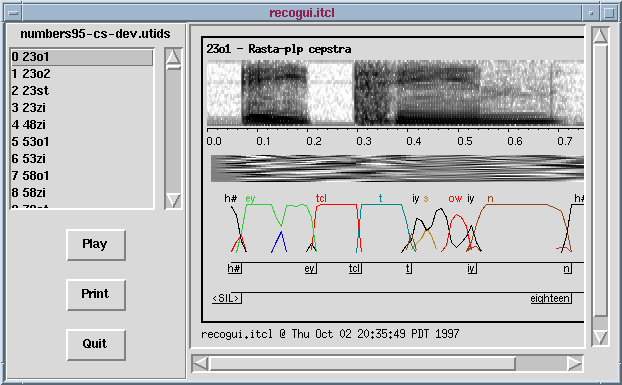
What it shows you for each recognizer is a spectrogram of the original sound (simple FFT-based with fixed parameter not related to the actual speech features). Below that is the time scale in seconds, then a grayscale image showing the actual feature frames fed to the neural net forward pass (rather uninformative for decorrelated cepstral-style features). Below that is a representation of the posterior probabilities emitted by the forward pass, which feed into the decoder; finally, when the decoder finishes, it generates backtrace information which is displayed as phone and word alignments.
The code currently resides in /u/dpwe/projects/recogviz/. The executable is recogviz (a shell script which normalizes the environment then launches the [incr Tcl] windowing shell), and you run it with something like:
./recogviz defaults=./defaults.def recog1=./recog1.def
defaults.def and recog1.def are parameter files (actually pure Tcl source) that define the recognizers to be used; the defaults file is intended to define the stuff that mostly stays the same, whereas the recog files define the very specific things.
Specifying recog2=... will cause the program to display a second recognizer underneath the first, feeding the same utterance to both (assuming the pfiles both conform to the same list file!).
Thus, for this demonstration, the defaults file contains the following:
# Useful constants set NUMBERSDIR "/u/drspeech/data/NUMBERS95" set DPWE "/u/dpwe/projects/NUMBERS95" set SULIND "/u/sulin/speech/project/numbers_cs" ## The list file that describes the order of utids in the pfile ## For our purposes, we're focussing on the numbers dev set set listfile "$NUMBERSDIR/list/numbers95-cs-dev.utids" set wavfilecmd "numbers95_findfile prefix=$NUMBERSDIR/ utid=%u" set samplerate 8000 set wavskewtime 0.0 set frametime 0.010 # Standard network geometry/type set mlp3_hidden_size 500 set mlp3_output_size 56 set mlp3_output_type softmax # Other common values set ftr_start 0 set ftr_window_len 9 # A single standard grammar & prononciation set for the numbers task set phone_models "$SULIND/400HU/lex/gildea90per-iter0.phone" set dictionary "$SULIND/400HU/lex/gildea90per-iter0.dict" set bigram "$SULIND/lm/numbers_cs_train.nbigram" set acoustic_scale 0.125
Then the definition file is few specifications needed to define a particular recognition strategy:
# A title for this set set title "Rasta-plp cepstra" # Actual definitions set ftr_file "$DPWE/pfiles/n95dev-lras-plp-cep.pf" set ftr_width 27 set norm_file "$DPWE/pfiles/n95tr-lras-plp-cep.norm" set weights "$DPWE/results/1997sep17/n95tr-embed+iter2.weights" set priors "$DPWE/results/1997sep17/n95tr-embed+iter3.priors"
Notice how the Tcl variable DPWE is defined in the defaults file but used in the recog file; this is OK because they're actually just executed by the Tcl interpreter one after the other.
These parameter files are just examples; if necessary, you could completely redefine the forward-pass and decoder invocations. But this structure should cover a number of interesting instances. Why not have a go!