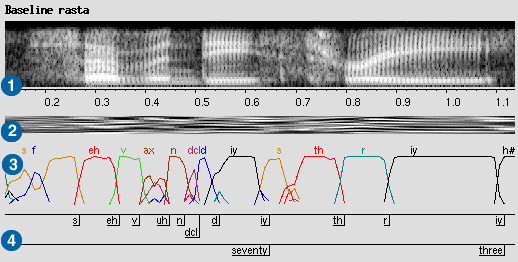
Conventional speech recognition proceeds through four stages, illustrated
by the four panes in the figure below (a screenshot from the recogviz
program). Initially the speech is stored as conventional digital audio,
as reflected by the spectrogram at the top ![]() . This signal is condensed
down to a smaller, normalized and decorrelated feature space, usually based
around the cepstral transform. In this example, there are 9 cepstral coefficients
along with the deltas (derivatives) and double-deltas for a total of 27
coefficients for every 10 ms chunk of sound
. This signal is condensed
down to a smaller, normalized and decorrelated feature space, usually based
around the cepstral transform. In this example, there are 9 cepstral coefficients
along with the deltas (derivatives) and double-deltas for a total of 27
coefficients for every 10 ms chunk of sound ![]() . These features form
the basis of the phoneme classifier, which is trained to associate particular
patterns of the feature vectors with specific phoneme labels. The ICSI system
uses a neural-net classifier, which estimates the posterior probability
of each of 56 phoneme labels for each frame of input. These 56 probabilities
always sum to 1, and are shown in the third panel
. These features form
the basis of the phoneme classifier, which is trained to associate particular
patterns of the feature vectors with specific phoneme labels. The ICSI system
uses a neural-net classifier, which estimates the posterior probability
of each of 56 phoneme labels for each frame of input. These 56 probabilities
always sum to 1, and are shown in the third panel ![]() . These probabilities
are the basis for the 'acoustic score' used by the Hidden Markov Model decoder
to find the most-likely sequence of phonemes and words in conjunction with
its specific models of phoneme segments, words and word sequences (i.e.
language model or grammar). The single 'best path' through the labellings,
known as the Viterbi path, results in a specific labelling of the original
sequence, including the recognized word sequence, shown in
. These probabilities
are the basis for the 'acoustic score' used by the Hidden Markov Model decoder
to find the most-likely sequence of phonemes and words in conjunction with
its specific models of phoneme segments, words and word sequences (i.e.
language model or grammar). The single 'best path' through the labellings,
known as the Viterbi path, results in a specific labelling of the original
sequence, including the recognized word sequence, shown in ![]() .
.
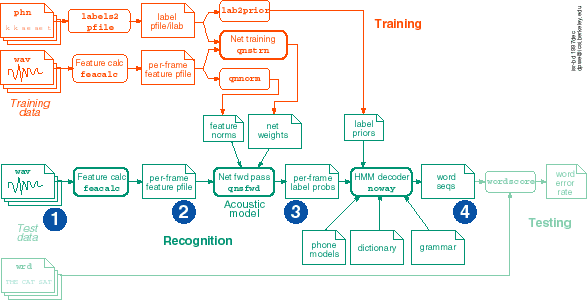
These four stages of processing are show again in the block diagram of speech recognition processing below. This diagram covers the training and testing of the recognizer as well as the simple recognition operation: The elements in dark green show the basic recognition path; Pale green shows the additional pieces involved in testing the recognizer (to get an overall word error rate (WER) figure that can be compared to other systems); the orange parts show the steps involved in training the neural-net classifier for a particular feature set, based on a training database of speech labelled with phonetic symbols. Training the classifier is the most time-consuming part of building a new speech recognizer; other steps include building the HMM speech-segment models and training the language models (not shown). In the figure, the rounded boxes correspond to the actual programs or scripts typically used at ICSI.
Now that you have seen the structure underlying the speech recognition process, you can build and test a recognizer for yourself by following the instructions in the standard training page.