In conventional training of a speech recognizer, a training set of speech signals which are already labelled with the 'correct' phonetic labels (often by human transcribers) are used to set the parameters of the classifier, which is then used during recognition to assign these labels to the frames in new signals. However, there may be a subtle mismatch between the transcribers' labellings in the training database and the intrinsic capabilites of the classifier: for instance, there may be a systematic (but functionally unimportant) bias between where a transcriber marks a boundary and where the classifier would most naturally place the boundary. Such a mismatch can compromise the training of the classifier, since it is expending modelling effort in reproducing aspects of the training labelling which are not necessary to the correct operation of the recognizer.
One approach to reducing or avoiding these effects employs an iterative process of training a classifier, then using this classifier to re-label the training examples (subject to the original word transcriptions), then training a new classifier starting from the relabeled training data, and so on. The idea is that if there are systematic timing biases in boundaries, or if there are questionable label assignments where a free choice exists within the prononciation lexicon, the relabelling will correct these, and the classifier trained in the next iteration will have a more consistent set of labels to train to, and thus will be a more accurate classifier. This process can be repeated indefinitely, although our experience is that iterations beyond the 4th yeild little or no additional gain.
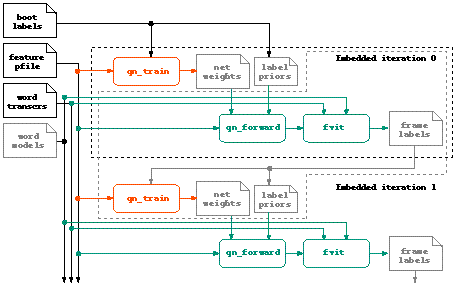
The block diagram below shows the processes involved in embedded training. In fact, the whole procedure is managed by a single script, dr_embed (whose parameters are well described in its man page). The diagram illustrates what this script actually does. Consistent with the block diagram in the overview page, orange boxes relate to training, and green to recognition. The gray boxes are the revised data files produced during each iteration.
The box marked fvit takes the place of the noway HMM decoder in conventional recognition. It is essentially doing the same job as a decoder - converting a set of per-frame label probabilities into a sequence of label assignments, employing a collection of word models - but whereas in conventional recognition it is necessary to test all possible word sequences as defined by the grammar, here the word sequence for each training utterance is defined in advance, and all that is required is to find the best match between those words and the acoustic signal. This process is known as "forced Viterbi alignment". Currently, it is performed through a special option to our old decoder, y0, although this is likely to be replaced.
[details taking you through running dr_embed on a NUMBERS example]